完成智能语音处理有关语音增强的实验后,发现周围同学找不到一些MATLAB有关的语音增强函数,为了可以方便后来人,我把我从GITHUB以及CSDN上“收罗”到的函数在这里进行分享,事不宜迟,请看下文!
给一段干净音频加粉红噪声
MATLAB官方工具箱中有一个关于音频的强大工具箱Audio Toolbox,里面自带了一个pinknoise的函数:
因此我们只要借助这个函数生成有关的加噪函数即可:
1 | %音频加粉色噪声函数 |
输入参数audioIn是不带噪声的原音频,输入参数snr是你期望加入噪声的信噪比,接下来展示如何使用这段函数:
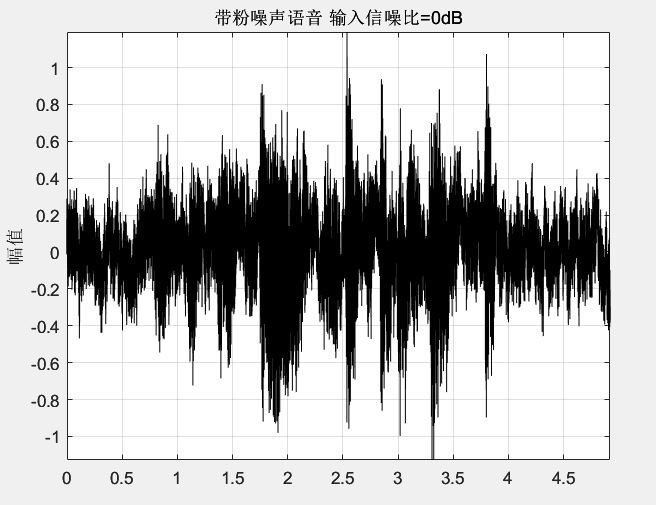
1 | [audio,fs] = audioread("F1.wav"); |
结果如下所示:
给一段干净音频加babble噪声(背景多人人声)
借助上述生成粉噪相同的思路我们就能够生成babble噪声,但问题是系统并没有自带生成babble背景多人人声噪声,因此我们换个思路,把该带有该噪声的数字音频数据导入(load)进Matlab中
1 | %音频加babble噪声函数 |
输入参数audioIn是不带噪声的原音频,输入参数snr是你期望加入噪声的信噪比,输入参数fs是原音频的频率,接下来展示如何使用这段函数:
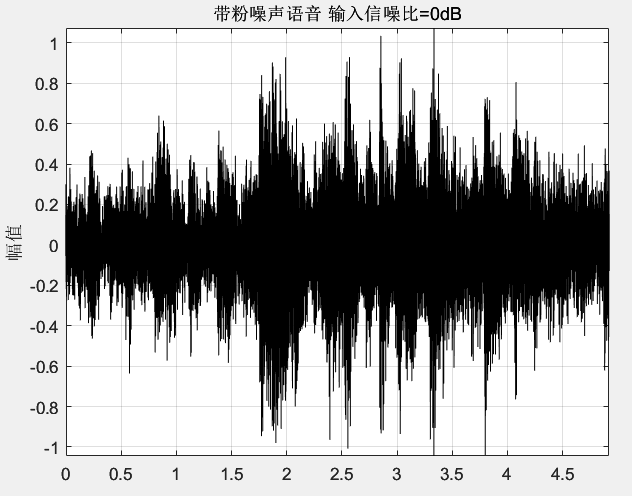
1 | [audio,fs] = audioread("F1.wav"); |
结果如下所示:
STOI函数
STOI(短时语音可懂度),这部分代码也是借助GITHUB链接:
STOI函数
1 | function d = STOI(x, y, fs_signal) |
PESQ函数
由于给出的PESQ代码过于长,在这里粘贴影响篇幅,因此给出GITHUB链接,读者自行前往链接复制粘贴。
(新手第一次写博客,如有错误和不好的地方,请多担待,另外对程序有问题请提出噢!)